




The rise of AI is shifting network demands, with data center interconnect (DCI) capacity becoming crucial to support AI infrastructure growth. Ciena’s Francisco Sant’Anna explains how for network operators, this shift unlocks exciting opportunities to deliver innovative, high-capacity connectivity solutions tailored to the needs of hyperscalers and AI powerhouses.
It is an exciting time for the networking industry. The AI boom marks an inflection point that is radically transforming the technology market. For telecommunications, it is comparable to the introduction of the internet and the smartphone —something that redefined the industry. AI’s expected impacts are complex and multifaceted, with one of its most intriguing angles being the anticipated shifts in connectivity demand. In this two-part blog series, we explore the AI trends and drivers transforming network demand and how operators can capitalize on them. Let’s start by discussing how AI investments are altering the data center interconnect (DCI) market.
Despite the current hype associated with the network impacts of AI, AI-driven traffic is still in its early days and not yet substantially augmenting data flows outside of data centers. However, additional connectivity capacity will be vital to sustain the growth of AI infrastructure and the evolution of AI models and applications. Securing such capacity is an integral part of investments that are already underway, creating tangible opportunities for network operators aiming to monetize AI demand. Now is the time to set out for success in AI infrastructure connectivity.
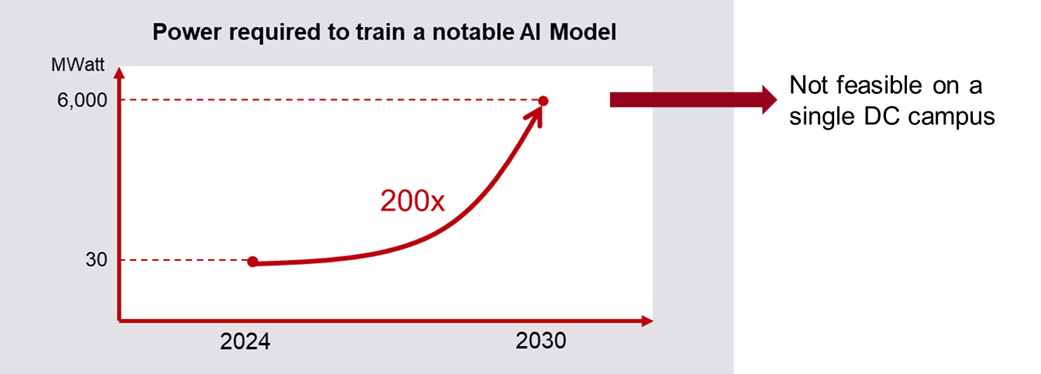
AI compute growth will translate into a 200-fold increase in power requirement
“Deep learning worked, got predictably better with scale, and we dedicated increasing resources to it.” Sam Altman’s words appropriately summarize the impressive evolution of AI models and its supporting infrastructure in recent years. Hyperscalers and AI powerhouses are investing billions of dollars to lead the AI race. They are building colossal AI training facilities to deliver ever more powerful large language models (LLMs). The compute load to train a cutting edge LLM is growing 4.7 times a year. This consistent trend points to a growth in training compute of leading AI models around 10,000 times over six years.
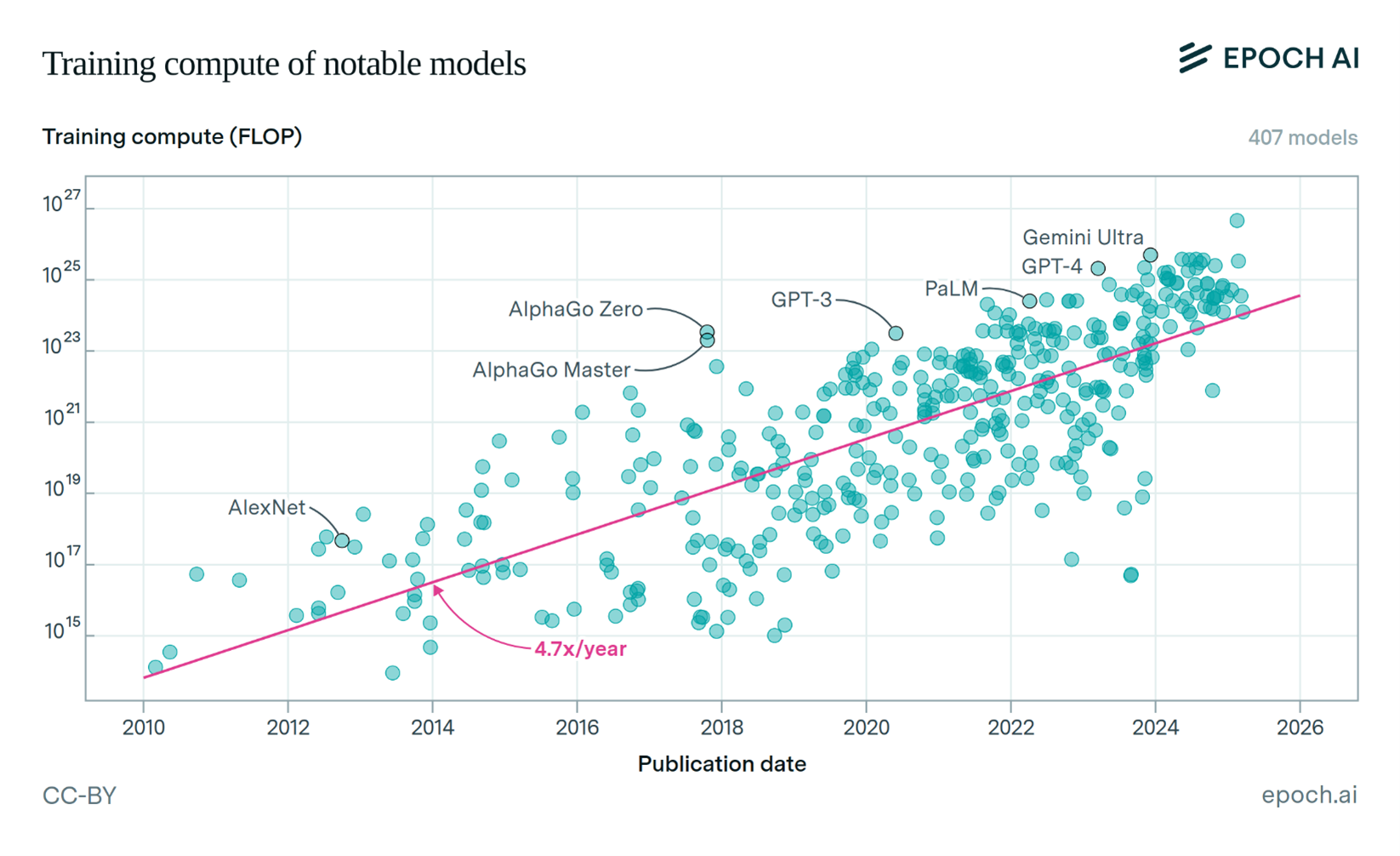 Training compute of notable AI models, from Epoch AI, ‘Data on Notable AI Models’. Retrieved from ‘https://epoch.ai/data/notable-ai-models’ [online resource]. Accessed 3 Apr, 2025.
Training compute of notable AI models, from Epoch AI, ‘Data on Notable AI Models’. Retrieved from ‘https://epoch.ai/data/notable-ai-models’ [online resource]. Accessed 3 Apr, 2025.
This increase in processing capacity is made possible through a combination of hardware performance improvements, longer training runs, and the deployment of tens of thousands of additional Graphics Processing Units (GPUs). As the industry discusses the challenges for sustaining the AI compute growth at this pace, there is consensus that the power to run these GPUs is the primary constraint (refer to epoch.ai/blog/can-ai-scaling-continue-through-2030 for a detailed analysis). It is expected that AI compute growth will translate into a 200-fold increase in power requirement over a six-year period.
To put this into perspective, leading LLMs in 2024 have consumed up to 30MW for their training, suggesting that training a notable model by 2030 could demand as much as 6GW. For context, only roughly two dozen of the world’s largest power plants currently exceed this output, making it unlikely to achieve such power availability in a data center campus in this timeframe. A viable alternative for powering such a massive compute load is to distribute it across various locations, far enough apart to utilize diverse power sources. While this approach may unlock the power bottleneck, it creates a new challenge: developing the techniques and infrastructure for geographically distributed training.
New algorithms may take diverse approaches to distributing the LLM training process. Typically, this involves breaking the training data into mini-batches and training a replica of the model at each data center using different mini-batches. After each training step—a complete optimization round of the model parameters running the subset of training data contained on the mini-batch—the replicas must synchronize their results. They exchange gradients with each other, averaging those to start the next round with a single shared updated set of weights.
The longer each exchange takes, the longer tens of thousands of GPUs will sit idle, waiting to start the next step. Given that a full training process can exceed a million steps, every second taken to transmit weights at every step may result in over ten days of delay in the process and millions of dollars in wasted compute resources. Considering current projections for the number of model parameters, we expect bandwidth demands of many petabits per second (Pb/s) will be necessary for an effective geographically distributed training process. The higher the bandwidth, the faster and more efficient the process.
While still somewhat under the radar for much of the industry, this type of demand has transitioned from trend to reality. Hyperscalers are now actively planning, procuring, and building the required infrastructure at an unrelenting pace. Google is among the few to publicly disclose distributed training initiatives, indicating Gemini Ultra was trained across multiple sites. However, despite the low profile, hyperscalers network teams seem empowered to make sure that connectivity won’t be the bottleneck for their AI success. They are exploring new architectures to run hundreds of fiber pairs in parallel and investing in the most advanced optical innovations to get the most out of each pair.
Network operators’ response
To capitalize on this opportunity, network operators are leveraging both technology and business model innovations. Historically, hyperscalers have favored building their own DCI networks. However, due to a combination of time-to-market pressures, business priorities, and regulatory constraints, they are increasingly open to alternative approaches for building their networks. On the other hand, service providers are seeking to meet hyperscalers’ demand through managed services, aiming to get more value from their existing fiber assets. That said, hyperscalers are very particular about design requirements, service levels, and the control and management of network assets, giving them influence over the evolution of the networks to support their AI infrastructure buildouts.
This is creating a perfect storm for Managed Optical Fiber Network (MOFN) deals. MOFN involves diverse business models for custom-built DCI solutions, where hyperscalers specify detailed network designs to be implemented by service providers and then offered as a service. Ciena has been facilitating many of these deals between service providers and hyperscalers by leveraging our trusted relationships and network technology leadership.
On top of flexible and custom-built MOFN solutions, hyperscalers and service providers are also leaning on optical innovations to make the most of every fiber pair. They are adopting reconfigurable line systems to unlock the L-band spectrum of their fibers, in addition to the traditional C-band. They are also implementing the latest coherent transponders that can deliver up to 1.6Tb/s per wavelength at much lower power and space per bit with advanced software applications to continually optimize optical asset performance. Furthermore, they are investigating multi-rail solutions to maximize the efficiency of DCI architectures with multiple fibers lit in parallel.
As ambitious as these networking aspirations may seem, they represent only a small fraction of the cost of the AI infrastructure they enable, making them a natural path to pursue.
Distributed LLM training is not the only driver of AI DCI opportunities. Whether for inference, training, or any combination of those, AI data center buildouts will be more geographically dispersed, as they follow energy availability while abiding by strict data sovereignty regulations. These critical facilities must be reliably and securely connected, further amplifying the demand for high-capacity DCI. This creates substantial opportunities for fiber-rich network operators in every region targeted for AI infrastructure investments that must not be neglected.
Let’s discuss how Ciena can help you make the most of DCI opportunities.